KD-Trees
A k-d tree (k-dimensional tree) is a binary search tree used to organize points in k-dimensional space. It supports efficient range and nearest-neighbor searches by recursively dividing space along alternating axes.
- The first split (e.g., x-axis) creates two regions.
- Each region is then split along the next axis (e.g., y-axis).
- Final split occurs along the z-axis (or next axis in higher dimensions).
- This creates compact, axis-aligned subregions ideal for search.
Construction
At each level, select axis = depth % k. Sort all points by that axis, then pick the median to split the space for balance. Recursively build left and right subtrees.
Complexity
| Operation | Average | Worst |
|---|---|---|
| Search | O(log n) | O(n) |
| Insert | O(log n) | O(n) |
| Delete | O(log n) | O(n) |
| Space | O(n) | O(n) |
Insertion & Deletion
Insertion compares the new point along the current axis at each level and places it as a leaf. Deletion may involve replacing the node with the subtree’s minimum on that axis, then rebalancing the subtree.
Balancing
KD-Trees avoid tree rotations. Balance is handled during construction using median splits. For dynamic data, K-D-B trees or periodic rebuilding maintain balance.
Nearest-Neighbor Search
- Recursively follow the split axis down to a leaf node.
- Track and update the nearest neighbor based on squared distance.
- If the hypersphere intersects the split plane, explore both subtrees.
- Use squared Euclidean distance to avoid square root calculations.
KD-Tree Nearest Neighbor Search Demo
Enter query point coordinates and click "Find Nearest Point" to see the nearest neighbor in the KD-Tree.
Locality Sensitive Hashing (LSH)
Locality Sensitive Hashing (LSH) is a dimensionality reduction technique used to efficiently find approximate nearest neighbors in high-dimensional spaces. Unlike traditional hashing, LSH is designed so that similar inputs are mapped to the same buckets with a higher probability than dissimilar ones. This allows for scalable and efficient similarity search without exhaustive comparisons.
LSH works by constructing multiple hash functions based on a chosen distance metric, such as cosine similarity or Jaccard similarity. These hash functions are applied to each input vector, and the results are used to index the vector into multiple hash tables. During a query, the input vector is hashed in the same way, and only the entries in the matching buckets are considered for comparison.
For example, in a system with one million image vectors, each of 128 dimensions, instead of comparing a new image with all one million vectors, LSH hashes the image vector and searches only in the relevant buckets. This drastically reduces the number of comparisons needed.
LSH is widely applied in tasks such as near-duplicate detection of images and videos, document similarity matching, plagiarism detection, and recommendation systems.
The diagram below illustrates the core idea: similar vectors are more likely to fall into the same buckets across multiple hash tables.

Trie Data Structures
A Trie (prefix tree) is a tree-based data structure used to efficiently store and retrieve strings. It is especially useful for prefix-based queries.

Each node represents a character. The path from the root to a node represents a prefix. This structure allows efficient lookups, insertions, and deletions.
Applications: Autocomplete, Spell Checking, IP Routing, etc.
Pseudocode
Pathfinding Algorithms: DFS, BFS, Dijkstra, A*
This section compares core pathfinding algorithms with side-by-side animation. Click any button to see how each algorithm explores nodes.
1. DFS (Depth-First Search)
DFS explores one branch deeply before backtracking. In this case, it follows A → B → D → G.
It chooses this path because it dives into B, then continues to D, and finally to G, even
though it is not the optimal path cost-wise.
2. BFS (Breadth-First Search)
BFS explores level-by-level. It finds A → B → E → G as the shortest path by number of edges, not cost. It explores neighbors before going deeper, making it optimal for unweighted graphs.
3. Dijkstra’s Algorithm
Dijkstra selects the lowest cumulative cost at every step. It also finds A → B → E → G as the minimum-cost path (cost = 7).
It avoids A → C → F → G and A → B → D → G as they are more expensive.
4. A* Algorithm
A* uses both actual cost and estimated cost (heuristic). With heuristics: A(6), B(4), E(2), it selects A → B → E → G as the optimal route combining cost-so-far and estimated cost to goal (f(n) = g(n) + h(n)). The heuristics are shown on the graph nodes.
Animated Visualization
PageRank Algorithm
PageRank is an algorithm that ranks nodes (like web pages) based on the importance of their incoming links. A node is considered more important if it is linked by other important nodes. The core idea is that importance flows through links.
The PageRank score of a node A is calculated using this formula:
PR(A) = (1 - d) / N + d × Σ [PR(i) / L(i)]
where:
- d = damping factor (usually 0.85)
- N = total number of nodes
- i = each node that links to A
- L(i) = number of outbound links from node i
Below is an animation where each node starts with an equal score. At every step, PageRank values are updated using the formula, and the node labels update to show the new score.
K-Means Clustering
K-Means is an unsupervised learning algorithm used to group similar data points into K distinct clusters. Each cluster is defined by a centroid — the mean of points in that group.
How K-Means Works
- Choose the number of clusters
K. - Initialize
Kcentroids (randomly). - Assign each point to its nearest centroid.
- Update centroids by calculating the mean of each cluster.
- Repeat steps 3–4 until centroids do not change.
Objective Function
The algorithm minimizes the within-cluster sum of squares (WCSS):
minimize ∑(k=1 to K) ∑(xᵢ ∈ Cₖ) ||xᵢ - μₖ||²
Choosing the Right K
- Elbow Method: Plot WCSS vs. K and choose the “elbow” point. Learn more
- Silhouette Score: Measures clustering quality. Higher = better. Learn more
Applications
- Customer segmentation
- Image compression
- Document clustering
- Anomaly detection
Source
The Elements of Statistical Learning by Hastie, Tibshirani, and Friedman
Animation: Watch how points connect to their centroids and clusters evolve.
DBSCAN Clustering
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) is a clustering algorithm that groups data points based on density. It can detect clusters of arbitrary shape and automatically label sparse regions as noise, without requiring the number of clusters in advance.
Key Parameters
- eps: Radius to search neighbors. Smaller values detect tighter clusters.
- min_samples: Minimum number of points within eps for a point to be considered a core point.
Types of Points
- Core Points: Surrounded by at least min_samples neighbors.
- Border Points: Close to a core point but not dense enough themselves.
- Noise Points: Do not meet criteria to belong to any cluster.
How It Works
- Select an unvisited point and find all neighbors within eps.
- If the number of neighbors ≥ min_samples, mark as core and expand cluster.
- Repeat recursively for each reachable point.
- Points not reachable from any cluster are marked as noise.
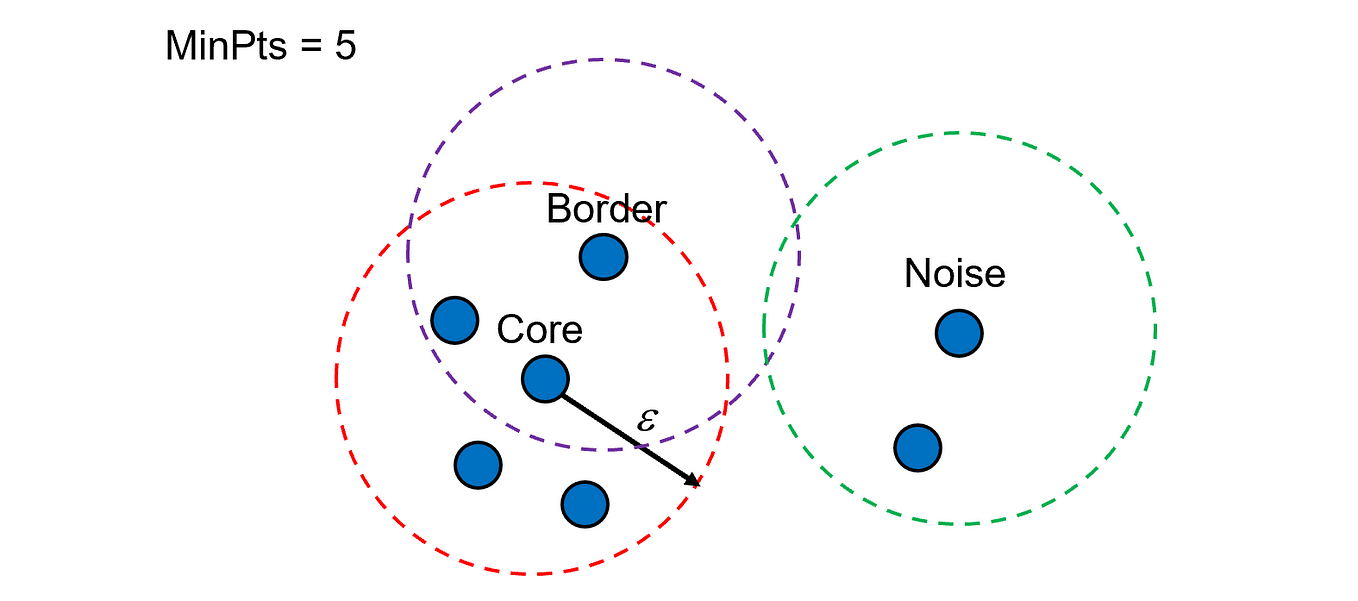
Source: Scikit-learn Documentation: DBSCAN
Hash Map
A hash map stores key-value pairs for efficient insertion, lookup, and deletion, usually with average time complexity O(1). It uses hash functions to compute an index and handles collisions via chaining or open addressing methods.
Good hash functions minimize collisions by spreading keys evenly. Worst-case time can degrade to O(n) if many collisions occur. The space complexity is O(n), proportional to stored key-value pairs.
Interactive Hash Map Animation
Insert keys and watch how the hash map stores and looks up values:
Time & Space Complexities
| Operation | Average Case | Worst Case |
|---|---|---|
| Insertion (put) | O(1) | O(n) |
| Lookup (get) | O(1) | O(n) |
| Deletion | O(1) | O(n) |
| Space Complexity | O(n) | |
Segment Tree
A Segment Tree is a powerful data structure used to efficiently performrange queries (like sum, min, or max over a subarray a[l…r]) and point or range updates, all in O(log n) time. Unlike prefix sums or naive array implementations, it offers both fast queries and fast updates, making it highly flexible.
The structure of a Segment Tree is based on a binary tree formed by dividing the array recursively into halves. Each node in the tree stores information (e.g., sum) about a specific segment of the array. This structure ensures that the height of the tree is O(log n) and uses at most 4n memory for an array of size n.
The tree is constructed in a bottom-up fashion starting from leaf nodes (individual array elements) and merging them upwards using an operation like addition. This construction takes O(n) time when the merge operation is constant time.
A major strength of Segment Trees lies in their support for advanced operations like lazy propagation, which enables efficient range updates (e.g., adding a value to all elements in a subarray) also in O(log n) time. Moreover, Segment Trees can be extended to higher dimensions, such as 2D Segment Trees for matrix operations, where queries can be answered in O(log² n) time.
Time and Space Complexities
| Operation | Time Complexity | Space Complexity | Description |
|---|---|---|---|
| Build | O(n) | O(n) | Constructs the segment tree from the initial array |
| Update (single element) | O(log n) | O(1) | Updates one element in the array and adjusts the tree accordingly |
| Query (sum / min / max) | O(log n) | O(1) | Queries the range sum, minimum or maximum over an interval |
| Range updates (lazy propagation) | O(log n) | O(n) | Updates entire subsegments efficiently using lazy propagation |
Segment Tree Visualizer
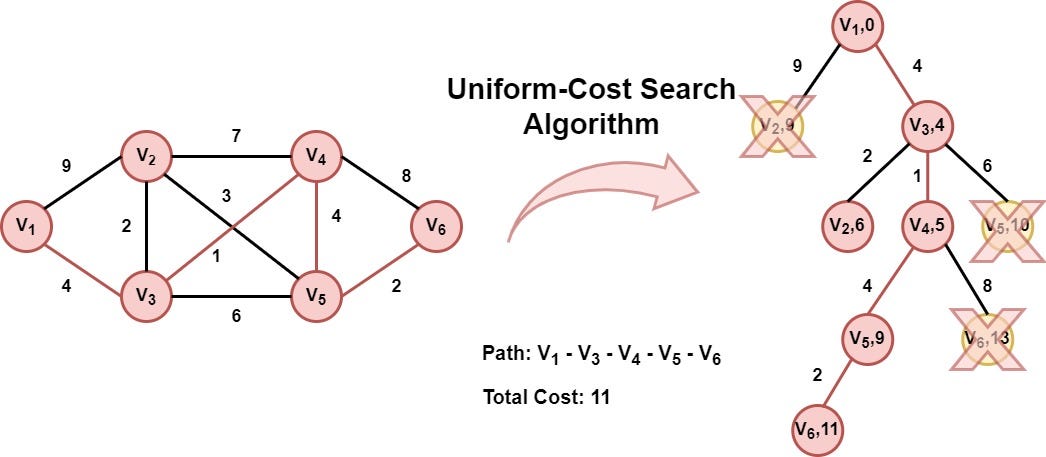
Uniform Cost Search
Uniform Cost Search (UCS) is a brute-force graph traversal algorithm used to find the path with the minimum cumulative cost from a source to a destination in a weighted graph. It is a type of uninformed search, meaning it doesn’t have any prior knowledge about the destination or heuristic guidance.
UCS functions similarly to Dijkstra’s algorithm. It expands the node with the lowest cost first using a priority queue where priority is determined by the cumulative cost to reach a node. It continues exploring the graph until it reaches the destination node with the least cost.
The algorithm uses a visited array to keep track of the explored nodes and ensures the shortest path is calculated without cycles. UCS is complete and optimal when all step costs are positive.
Time Complexity: Exponential in the worst case, especially when the minimum step cost ε is small relative to the optimal cost C. It is approximately O(bC/ε) where b is the branching factor.