Introduction & Problem Statement
The rise of e-commerce has transformed how consumers shop, providing convenience and vast product choices. However, this rapid growth has also led to an increase in counterfeit products infiltrating online marketplaces. Amazon, as one of the world’s largest platforms, faces significant risks from fake or duplicate listings—especially involving popular brands like Apple and Nike. These counterfeit items not only damage brand reputation but also erode customer trust and satisfaction.
While Amazon has implemented programs such as Brand Registry and Project Zero to address this issue, these solutions largely act after counterfeit listings have already appeared. This reactive approach places too much reliance on brands and customers to identify and report fake products, allowing many counterfeit listings to slip through undetected. There is a critical need for a proactive, automated system that can identify and block counterfeit sellers and listings before they reach customers. This business case proposes such a solution, leveraging advanced data structures and AI-driven algorithms to enhance authenticity verification and safeguard the integrity of Amazon’s marketplace.
Objectives
- Proactively detect counterfeit listings
- Safeguard consumer trust
- Protect brand reputation
- Streamline seller verification
System Flow Diagram
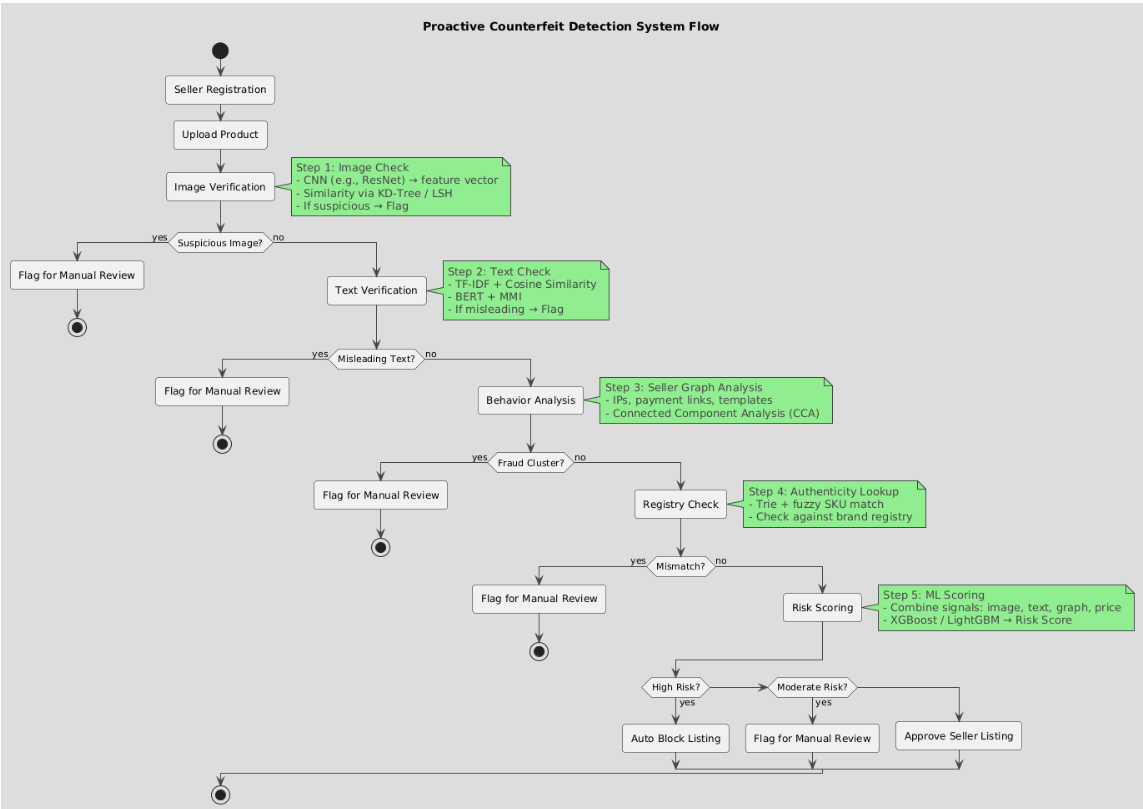
Proposed Solution
To proactively prevent counterfeit products on Amazon, the proposed system leverages advanced AI-powered techniques to automatically verify new sellers and their product listings before they are published. This approach reduces reliance on reactive reporting and manual intervention by brands and customers, enabling faster detection and blocking of counterfeit items. The system integrates image similarity matching, seller behavior analysis, and automated decision-making to maintain the integrity of Amazon’s marketplace.
Step 1:
Seller Registration and Data Collection
When a new seller attempts to register or list a product on the platform, the system gathers comprehensive information including product images, detailed descriptions, pricing, SKU and seller metadata. Although new sellers may not have transaction history at the point of registration, the system continuously monitors sellers’ transaction history once they begin selling.
Step 2:
Image Verification Against Trusted Database
When a seller uploads product images, the system transforms these images into high-dimensional feature vectors using
deep convolutional neural networks (CNNs) like ResNet or MobileNet. These feature vectors are complex numerical
representations that capture subtle visual details—such as textures, shapes, and color gradients—enabling more accurate
comparison beyond simple pixel matching.
To efficiently manage this data, advanced structures like
KD-Trees organize and accelerate nearest neighbor
searches when the dataset is moderate in size.
Locality Sensitive Hashing(LSis used for very large
databases with millions of images. LSH hashes similar feature vectors into common buckets with high probability, enabling fast
approximate nearest neighbor searches that balance accuracy and speed at scale.
This system detects images closely resembling authentic products but with subtle anomalies—such as misaligned logos or unusual color shifts—that often indicate counterfeits. Flagged listings then proceed to further checks like seller behavior analysis or manual review before a final decision on legitimacy. For example, the system could flag an image saying, “This looks 90% like an Apple iPhone 14, but the logo seems off, so it needs a closer look.”
Step 3:
Textual Description & Title Verification
Counterfeit listings often try to appear legitimate by using misleading titles or buzzword-filled descriptions. This step verifies whether the submitted text aligns with genuine product data.
First, we use TF-IDF combined with cosine similarity to compare the title and description of a new listing against a trusted database of authentic product descriptions. This helps us identify listings that use the correct keywords in the right context. To go beyond surface-level keyword matching, we apply BERT embeddings , which capture the deeper semantic meaning of the text. This allows the system to detect descriptions that might appear correct on the surface but are actually vague or misleading. A key part of this step is the use of Maximum Mutual Information(MMI) . MMI measures how much meaningful information is actually shared between the seller’s text and verified product data.
It helps identify listings that simply repeat popular terms or use slight misspellings—like “Applle” instead of “Apple”—without conveying real, informative content. Listings with low mutual information are flagged as suspicious. example: A fake listing like “New Applle iPhonexx — 100% Original, Super Phonee, Buy Now!” might score high on TF-IDF due to keyword overlap like "Apple" and "iPhone." However, MMI gives it a low score because it lacks meaningful, informative content found in genuine listings—like technical specs or real features—revealing it's likely trying to mislead buyers.
Step 4:
Seller Behavior & Network Analysis Using Connected componded Analysis(CCA)
Even if a product’s images and descriptions seem authentic, it’s critical to evaluate the seller's background to catch hidden fraud. Many counterfeiters work through coordinated seller networks, not just single fake accounts. This is where Connected Component Analysis (CCA) helps.
CCA is a graph-based algorithm used to detect groups of entities that are directly or indirectly linked. In our use case, each seller is represented as a node in a graph, and connections (edges) are formed based on shared suspicious characteristics — such as common IP addresses, repeated product templates, linked payment methods, or mutual buyer-review circles.
Once these connections are mapped, CCA identifies "components" — tightly-knit seller clusters. If one or more members of a component are involved in fraudulent activity, the entire group can be flagged for further scrutiny.
example:- Seller A and Seller B operate from the same IP address
- Seller B and Seller C post near-identical fake listings
- Seller C has already been banned for selling counterfeits
At first glance, Seller A may appear trustworthy. But by using CCA, all three sellers are identified as part of a single fraudulent cluster. The system automatically flags this group, preventing coordinated fraud that might otherwise go undetected if sellers were analyzed in isolation.
Step 5:
After verifying product images in Step 2 and analyzing seller networks for suspicious activity in Step 3, some counterfeit listings can still slip through. Step 4 adds an important layer of product-level verification and combines all the signals into a unified risk score to improve detection accuracy and make enforcement scalable.
- 4a. Product Authenticity Registry Lookup
Product identifiers like SKUs, barcodes, or serial numbers are hashed securely and checked against a brand-approved authenticity registry. This protects data privacy while ensuring integrity.
To catch tricky cases like typo squatting—where sellers replace letters with similar-looking numbers (e.g., “Appl3” instead of “Apple”)—the system uses Fuzzy Matching techniques . The Trie efficiently stores all valid product names or SKUs in a prefix tree, allowing fast lookups. When a new product name is checked, the system navigates the Trie while allowing a limited number of character substitutions, insertions, or deletions, as determined by the fuzzy matching algorithm (like Levenshtein distance). This way, it can quickly identify near-matches even if the name is slightly altered or misspelled. Listings with SKUs that are missing from or flagged by the registry are then marked as potentially counterfeit.
- 4b. Risk Scoring Engine
This engine takes multiple inputs and combines them into a single risk score, including: Visual similarity scores from the deep learning image analysis (Step 2) Seller risk scores derived from detecting suspicious seller clusters using Connected Component Analysis (Step 3) Price anomaly checks for listings priced way below market value Text analysis that flags keyword deception or manipulation Results from the authenticity registry lookup (SKU validity) All these features feed into a machine learning model—such as XGBoost or LightGBM—trained on historical data of genuine and fake listings. The model outputs a normalized risk score (between 0 and 1, or 0 and 100) showing the likelihood that the listing is counterfeit.
Outcomes
- Listings that receive high risk scores would be automatically blocked or flagged for manual review.
- Listings with low risk scores could be approved and might earn a “trusted seller” badge to help increase buyer confidence.
Business Impact
- Blocks counterfeit listings before they go live, rather than reacting after customer or brand reports.h
- Strengthens customer trust by ensuring only authentic products appear on the platform.
- Protects the reputation of top brands by proactively filtering fake listings.
- Minimizes revenue loss caused by fraud and returns linked to counterfeit items.
- Speeds up the verification process for genuine sellers, improving onboarding.
- Enhances the overall integrity and credibility of Amazon’s marketplace.
Future Implications
- Integrate natural language generation (NLG) models to automatically generate alerts and detailed reports for manual reviewers, speeding up the review process.
- Incorporate real-time price anomaly detection using market trend data to more accurately flag suspiciously low-priced listings.
- Expand image verification to include 3D model analysis and video content checks for products with multimedia listings.
Conclusion
This system offers a proactive and effective approach to tackling counterfeit products on Amazon. It effectively addresses the limitations of current reactive approaches. By combining AI-driven image and text verification with seller behavior analysis, this solution will help restore buyer confidence, safeguard Amazon’s marketplace integrity, and ultimately drive sustainable business growth.
📄 Download PDF