Introduction & Problem Statement
Efficiently managing inventory and deliveries is a major challenge for large e-commerce companies. With multiple warehouses storing thousands of products, it’s important to keep track of stock levels and know when restocking is needed. At the same time, planning delivery routes that minimize cost and time is essential to ensure smooth operations and satisfy customers. The problem is to build a system that can quickly process large amounts of inventory and logistics data to identify low-stock warehouses and find the best delivery routes, even as conditions like traffic and demand change.
Objectives
- To keep real-time track of inventory levels across multiple warehouses accurately.
- To plan the most cost-effective delivery routes for restocking warehouses.
- To reduce delivery delays and minimize transportation costs by optimizing routes.
System Flow Diagram
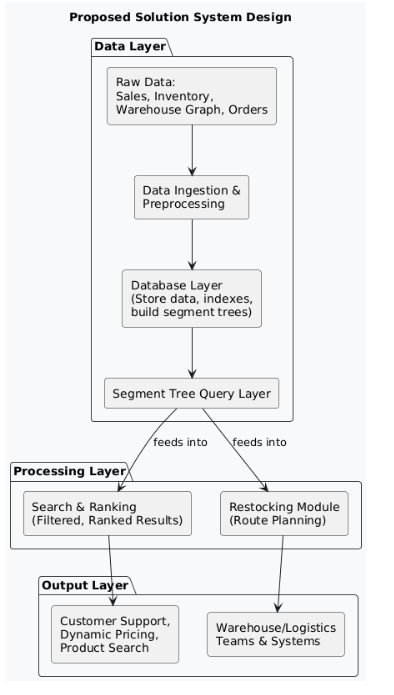
Proposed Solution
The proposed solution focuses on keeping track of inventory and sales data in a way that allows fast and easy searching. It uses a method to quickly find products and orders based on different conditions like price or date. For restocking, it plans delivery routes that cost the least, ensuring warehouses get supplies on time without wasting resources. The system connects all these parts so that decisions about pricing, stock, and deliveries can be made quickly and smoothly, helping both the business and customers.
Step 1:
Data Modeling & Preparation
In Step 1, all important data is collected and organized, including inventory and sales details like product IDs, prices, categories, stock per warehouse, and sales history. The warehouse network is represented as a weighted graph showing warehouses as nodes and routes as edges with costs such as distance and fuel. Customer orders with relevant details are also gathered. This well-structured data is crucial because it lays the foundation for building efficient segment trees in the next step. Proper preprocessing, such as normalizing and compressing attributes, ensures fast indexing and allows the warehouse graph to update dynamically with real-time route costs. Without this clean data preparation, the fast queries and updates needed in Step 2 wouldn’t work effectively.
Step 2:
Build and Use Segment Trees for Fast Queries
In Step 2, segment trees are built on important attributes like product price, stock levels, and sales dates to allow fast range queries and updates. Each segment tree node holds aggregated data, such as total stock within a price range, enabling quick answers to questions like "How much stock is there for electronics priced between ₹500 and ₹1500?" When sales happen, the trees update efficiently, keeping data current.
This fast querying system plays a key role in the next steps. It helps filter products or orders quickly so the ranking model can focus only on relevant items, improving search speed and accuracy. At the same time, it continuously monitors stock levels across warehouses, signaling when restocking is needed and triggering route planning for deliveries. Without this efficient data structure, real-time decision-making for both ranking and logistics would be much slower and less reliable.
Step 3:
ML-Powered Search Ranking
After segment trees filter down large data sets into relevant candidates, this step applies machine learning ranking models (like LambdaMART) to sort products or orders based on relevance. These models are trained on past data to understand what matters most to users — helping show the right items faster in search results or support tools. This not only improves customer experience but also reduces the computational load on ranking systems since they work only on pre-filtered data.
The output from this step also influences logistics — highly ranked, fast-moving products help signal which items might need quicker restocking, feeding into the routing decisions in the next step. So, ranking here does more than just search — it shapes supply priorities too.
Step 4:
Optimal Routing with Uniform Cost Search (UCS)
Based on low-stock alerts from segment trees, (UCS) is used to compute the most efficient delivery routes from central warehouses to those needing restocking. The entire warehouse network is modeled as a graph, where edges carry real-time costs like distance, traffic delays, or fuel usage. Uniform Cost Search (UCS) finds the lowest-cost path without needing extra heuristics, making it perfect for Amazon’s constantly changing logistics. This step ensures stock is moved quickly and economically — directly driven by the inventory signals generated in Step 2.
Step 5:
Continuous Feedback Loop
Once deliveries are made, inventory data is updated and fed back into the system. This refreshes the segment trees, adjusts rankings, and can trigger new routing actions if needed. This loop keeps the system adaptive, ensuring real-time responsiveness to stock changes, customer demand, and shifting logistics conditions.
Outcomes
- Listings that receive high risk scores would be automatically blocked or flagged for manual review.
- Listings with low risk scores could be approved and might earn a “trusted seller” badge to help increase buyer confidence.
Business Impact
- Reduced handling time, improved customer satisfaction (CSAT), and lower support costs.
- Lower holding costs, higher inventory turnover, and improved product availability.
- Reduced shipping costs, faster delivery, and better warehouse utilization.
Conclusion
This solution seamlessly integrates segment trees for fast inventory insights, A9-style ranking for smart search, and UCS for efficient restocking routes. Together, they create a dynamic, responsive system that improves product discovery, optimizes logistics, and enhances customer experience — while laying the foundation for future AI-driven fulfillment at scale.